Scraping and Cleaning Data from VGChartz
by Bayne Brannen
Summary
I use Scrapy and pandas to build a web crawler to retrieve video game statistics from VGChartz.com and clean the resulting dataset.
- Python
- Web scraping with scrapy
- Data cleaning with pandas
One of my favorite parts about data science is figuring out just how to get the data I need. As I’ve always had a distinct interest in the video game industry, I was looking for a video game dataset that might provide some interesting datapoints on the industry. I found this dataset by Kaggle user ashaheedq which does contain a lot of interesting features about certain video games. The dataset was scraped from the website VGChartz which—among other things—catalogues video game releases (both series and individual games) and provides statistics ranging from critical scores to total units shipped to sales figures. The dataset looked pretty interesting, but it was missing a categorical data point for each game that I wanted for analysis: genre. So I decided to set about building my own web scraper and—as an extra challenge—decided not to look at the scraping code ashaheedq used.
The data is presented in what is essentially a dataframe/table format which I thought would make it rather straightforward to scrape, and in some ways, this was true. Of course, there is no way to download this data as a .csv on the website and it is impossible to pull up all the data on one page. So I needed a web crawler that would allow me to cycle through these pages.
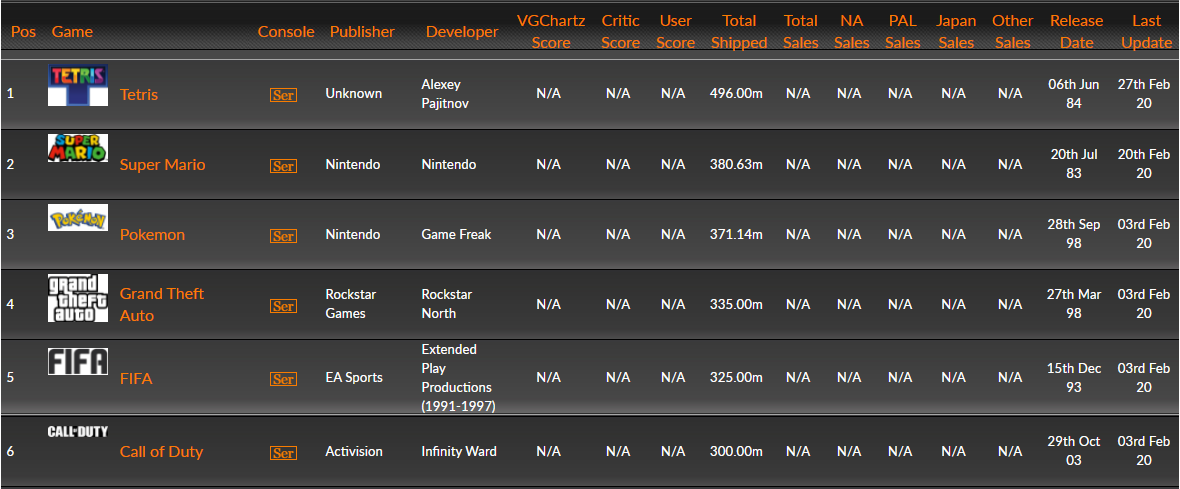
However, there’s another issue. As you’ll see, the above table does not contain a column indicating the genre of the game. Since this was essentially the entire reason I wanted to scrape the data myself, I had to find a solution. While there is no genre column, there is a genre filter on the website that can be applied through a dropdown. This filter alters the URI of the web address to bring up a list of games only with the genre selected. By altering the URI in this same way I will be able to cycle through all of the games with that genre labeling each of those games with that genre. So I will start by making a list of all of the genres that are available.
genre_list = ["Action, Adventure, Action-Adventure, Board Game, Education, Fighting, Misc,
MMO, Music, Party, Platform, Puzzle, Racing, Role-Playing, Sandbox, Shooter, Simulation,
Sports, Strategy, Visual+Novel]I am going to use a Scrapy webcrawler to retrieve the data itself. I followed this tutorial to get started and used the documentation to create the actual pipeline. For this project, I decided to use a JSON writer pipeline. Essentially, the Scrapy “Spider” will access the url, and then use the pipeline object to take the data in as a Julia file in a JSON format.
class JsonWriterPipeline(object):
def open_spider(self, spider):
self.file = open('gamesresult.jl', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return itemNow to build the actual Spider. There are several things to touch on here, so I’ll start at the top. First, I establish a couple variables that I will use as global variables in the scraper. I created a page and a genre variable. I have set the page as “2” because this is where the Spider will go after it finishes the first page, and then will iterate until it gets through all of the pages. Then I have a genre variable which is a number referring to the place each genre has on the list I created at the beginning of this file.
Within the Spider, I will name the Spider and supply it with its start URL. The default page does not include all columns, so this URL has a lot added to the URI to make sure that it is collecting as much data as possible. Additionally of course, it adds the correct genre to the URI to makes sure we are only looking at the relevant genre of games and can add this data to the JSON.
class VGSpider(scrapy.Spider):
global genre
name = "game_spider"
full_url = 'https://www.vgchartz.com/games/games.php?name=&keyword=&console=®ion=All&developer=&publisher=&goty_year=&genre=%s&boxart=Both&banner=Both&ownership=Both&showmultiplat=No&results=200&order=Sales&showtotalsales=0&showtotalsales=1&showpublisher=0&showpublisher=1&showvgchartzscore=0&showvgchartzscore=1&shownasales=0&shownasales=1&showdeveloper=0&showdeveloper=1&showcriticscore=0&showcriticscore=1&showpalsales=0&showpalsales=1&showreleasedate=0&showreleasedate=1&showuserscore=0&showuserscore=1&showjapansales=0&showjapansales=1&showlastupdate=0&showlastupdate=1&showothersales=0&showothersales=1&showshipped=0&showshipped=1'
start_urls = [fullurl % (genre_list[0])]With the “custom_settings” attribute that comes part and parcel with the Spider object from the Scrapy library. With this attribute, I can make sure the above writer pipeline is actually implemented, and can also set the feed format so that the output of the crawler is JSON.
custom_settings = {
'LOG_LEVEL': logging.WARNING,
'ITEM_PIPELINES': {'__main__.JsonWriterPipeline': 1},
'FEED_FORMAT':'json',
'FEED_URI': 'gamesresult.json'
}Then there’s the more exciting part of the Spider, the parse function which is what will actually parse the HTML of the page. Next, I will assign a host of selector variables that will provide the path (in this case the equivalent of the column number for the HTML table object). And then I run a for loop that will go through each row of the table currently on the page, and using my previously assigned selector variables to find the right piece of data and use the yield function (not return so that the function can continue to run) to send each piece of data into the correct part of the JSON file.
This allows me to collect everything that is currently on the screen, but now I need my crawler to go to the next page. And now we add the ‘page’ parameter to the URI and use the number from the global page variable we initialized before the Spider began. And then—this is kind of fun—I use a new selector variable that I call the RESULTS_SELECTOR to grab the text that tells us how many results our search had. I then use a regular expression to grab the number, convert it to an integer, and divide it by 200. Since there are 200 results per page, this simple math yields how many pages there will be for this genre.
page_url = "https://www.vgchartz.com/games/games.php?page=%s&results=200&name=&console=&keyword=&publisher=&genre=%s&order=Sales&ownership=Both&boxart=Both&banner=Both&showdeleted=®ion=All&goty_year=&developer=&direction=DESC&showtotalsales=1&shownasales=1&showpalsales=1&showjapansales=1&showothersales=1&showpublisher=1&showdeveloper=1&showreleasedate=1&showlastupdate=1&showvgchartzscore=1&showcriticscore=1&showuserscore=1&showshipped=1&alphasort=&showmultiplat=No"
RESULTS_SELECTOR = '//*[@id="generalBody"]/table[1]/tr[1]/th[1]/text()'
results = response.xpath(RESULTS_SELECTOR).extract_first()
results_pat = r'([0-9]{1,9})'
results = results.replace(",", "")
last_page = math.ceil(int(re.search(results_pat, results).group(1)) / 200)After this, I just have some if statements to figure out if the scraping is over with or not. The first one determines whether or not the scraper is beyond the last page of the genre Visual Novel. Visual Novel is the final genre in the list, so this would mean that the Spider is done with Visual Novel and thus done with scraping in general. If the Spider exceeds the last page, but it is not scraping the Visual Novel genre that just means it’s past the last page of that particular genre's results. The follow if statement, iterates the Spider onto the next genre, puts together a URL for the first page of that genre, and then continues scraping. If the last page hasn’t been exceeded at all, then the Spider should just keep iterating by page and stick with the same genre. So the page of the URL will change, but everything else will stay the same and the Spider keeps going. Note that I add in a sleep function here, this is just so I don’t overload the VGChartz website with too many requests.
if (page > last_page) & (genre_list[genre] == "Visual+Novel"):
print(genre_list[genre])
return "All done!"
elif (page > last_page) & (genre_list[genre] != "Visual+Novel"):
print(genre_list[genre])
page = 1
genre += 1
next_page = "https://www.vgchartz.com/games/games.php?page=%s&results=200&name=&console=&keyword=&publisher=&genre=%s&order=Sales&ownership=Both&boxart=Both&banner=Both&showdeleted=®ion=All&goty_year=&developer=&direction=DESC&showtotalsales=1&shownasales=1&showpalsales=1&showjapansales=1&showothersales=1&showpublisher=1&showdeveloper=1&showreleasedate=1&showlastupdate=1&showvgchartzscore=1&showcriticscore=1&showuserscore=1&showshipped=1&alphasort=&showmultiplat=No"
next_page = page_url % (str(page), genre_list[genre])
yield scrapy.Request(
response.urljoin(next_page),
callback=self.parse
)
page += 1
else:
next_page = page_url % (str(page), genre_list[genre])
yield scrapy.Request(
response.urljoin(next_page),
callback=self.parse
)
time.sleep(3)
page += 1Then I let the Spider go, and it takes approximately 20-30 minutes to grab the data it needs. After I completed the scraping project, I checked Kaggle user ashaheedq’s code to see how they accomplished a similar project. Their version apparently took around 30-40 hours. It turns out that his crawler cycled through each game’s info page individually. Mine essentially does this in bulk by extracting the data from these tables using the search function rather than going game-by-game. The only data they retrieved that mine couldn’t was ESRB ratings which would be a consideration for anyone wanting to use either of our scrapers to grab this data. If you wanted to scrape in less time and wanted a genre column, you could use my scraper; theirs would take a lot longer but would be useful if you specifically wanted ESRB ratings and didn’t care about genre. Though, you probably could tweak their code to get genre as well if you wanted, ESRB ratings are simply not an option for the way that my scraper retrieved the data.
So now I’ve got the data, but it’s not likely to be in the best condition. Time to move on to every data scientist’s favorite pastime—cleaning the data. First I’m going to read in the JSON file as a pandas dataframe.
games = pd.read_json("gamesresult.json")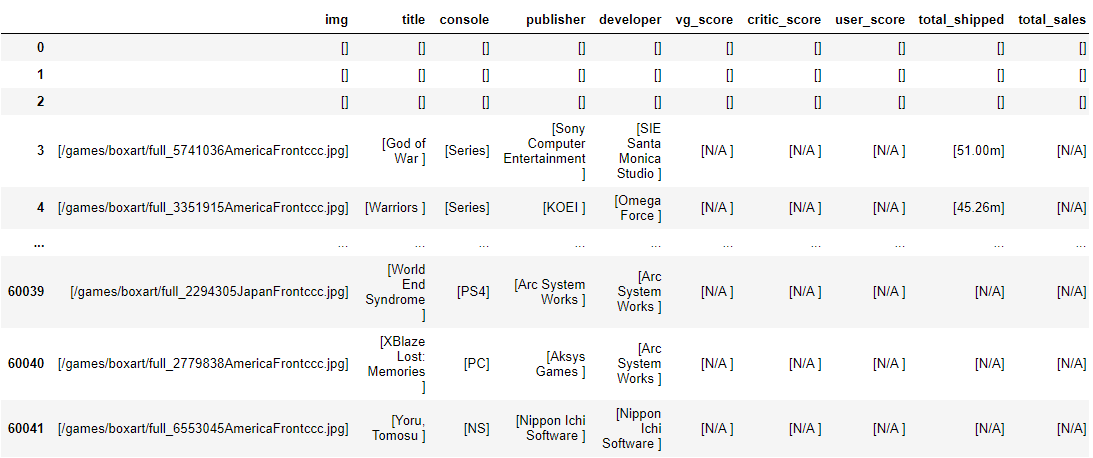
Phew, that’s no good—time to get cleaning. Now, the way that the HTML on the webpage was constructed and the method my scraper used to retrieve it, there are a few basic things to clean up here. Firstly, there are three blank rows for each page the scraper pulled (just a part of the HTML table object), so an easy fix is to just filter out any rows that don’t have a game title in the title column. I wouldn’t want a row like that anyhow.
games = games[~(games["title"].str.len() == 0)] You can also see that each datapoint is part of a single element list, so I will use a vectorized lambda function to extract the single element out of the list.
for column in ['console', 'critic_score', 'developer', 'img', 'jp_sales',
'last_update', 'na_sales', 'other_sales', 'pal_sales', 'publisher',
'release_date', 'title', 'total_sales', 'total_shipped', 'user_score',
'vg_score']:
games[column] = games[column].apply(lambda x : x[0])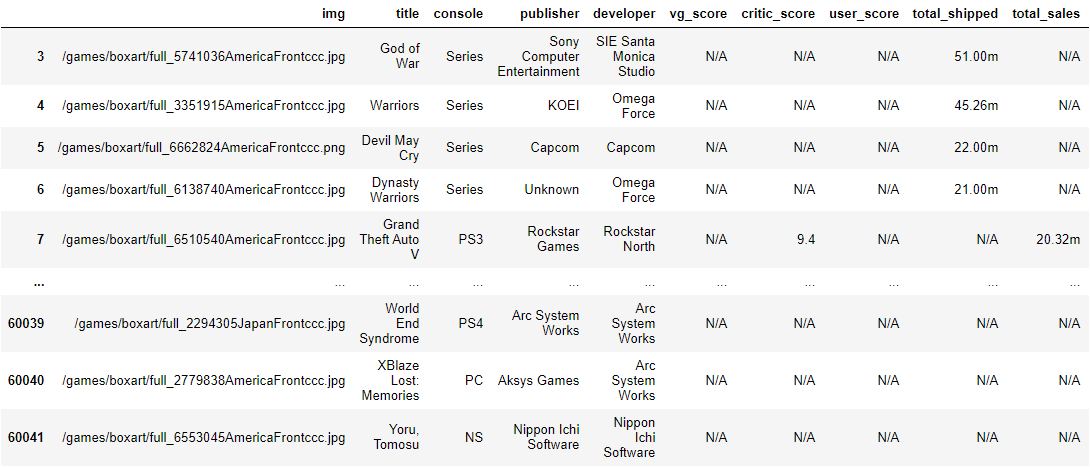
Ah, that’s better. It’s hard to tell, but there are some trailing spaces on some of these values, so I will remove those as well using strip() one of the vectorized string functions built into the pandas library. I’m also going to replace any “N/A” strings with actual NaN values.
games = games.apply(lambda x : x.str.strip())
games = games.replace("N/A", np.nan)Just to make it clear what I’m doing next, I’ve created a function called “clean_nums” that will reformat all of the numbers in the dataset to usable float data types instead of strings. This function applies two vectorized functions across whatever column is added. It will strip the character “m” off all specified columns and then will convert the data to type float. I run a quick for loop to go through each column and run this function.
def clean_nums(column, dataframe):
dataframe[column] = dataframe[column].str.strip("m")
dataframe[column] = dataframe[column].apply(lambda x : float(x))
sales_columns = ["na_sales",
"jp_sales",
"pal_sales",
"other_sales",
"total_sales",
"total_shipped",
"vg_score",
"user_score",
"critic_score"]
for column in sales_columns:
clean_nums(column, games)Next, I’ll reformat the dates which are presented in a very non-Python friendly format (e.g. 22nd Mar 05). Here I use a combination of regular expressions to extract the day, month, and year from each aspect of the string we already have. The year and day are fortunately already in numerical form. But for the month, I created a dictionary to translate the string version of the month to a numerical value (e.g. “Mar” corresponds to 3). Then I create a function that takes in a text value, uses the regex to extract the proper numbers, and returns the whole thing as a datetime value. Note that for the year value, we only get the last two digits. Fortunately, we can go ahead and assume that any pair of digits that begins with a seven or higher is from the 1900s. Video games didn’t really exist before 1970, and that’s the earliest date in the dataset. Any pair of digits that begins with a number less than or equal to six we can assume to be in the new millennium. For either case, I add a ‘19’ or ‘20’ in front of the two digits to give us the full year. This won’t be accurate forever, but for the next 50 years we can feel pretty confident it will work just fine.
day_pat = r"([0-9]{2})(?=[a-z]{2})"
month_pat = r"([A-Z][a-z]{2})"
year_pat = r"([0-9]{2}(?![a-z]{2}))"
month_to_num = {'Sep' : 9,
'Jul' : 7,
'Oct' : 10,
'Mar' : 3,
'Dec' : 12,
'Feb' : 2,
'Nov' : 11,
'Jun' : 6,
'Aug' : 8,
'May' : 5,
'Apr' : 4,
'Jan' : 1
}
def clean_dates(text):
global day_pat
global month_pat
global year_pat
global month_to_num
if text is np.nan:
return text
day = int((re.search(day_pat, text).group(1)))
month = month_to_num[(re.search(month_pat, text).group(1))]
year = (re.search(year_pat, text).group(1))
if int(year[0]) >= 7:
year = int("19" + year)
else:
year = int("20" + year)
return(datetime.datetime(year, month, day))
for column in ["last_update", "release_date"]:
games[column] = games[column].apply(lambda x : clean_dates(x))We’re almost done. Just an easy clean-up of the genre column which still has a “+” instead of a space between words.
games["genre"] = games["genre"].str.replace("+", " ")Great, and then while exploring this data I noticed there were some impossible release date values that seemed to be accidentally given some sort of dummy date. These dummy dates usually fall on two extremes: the last day of the current year or in 1970. So the code checks the current year and replaces any games that were supposedly released on the last day of the current year (which more than likely hasn’t happened yet) and replaces the release date with a NaN value. It does the same for any game with a release date in 1970 (no video games were released in 1970).
todays_date = date.today()
todays_year = todays_date.year
games.loc[games["release_date"] >= datetime.datetime(todays_year, 12, 31), "release_date"] = np.nan
games.loc[games["release_date"].dt.year == 1970, "release_date"] = np.nanThat’s it! My data set is clean, so I’ll just export it and give it a name that denotes the date it was created.
games.to_csv("vgchartz-"
+ str(date.today().month)
+ "_"
+ str(date.today().day)
+ "_"
+ str(date.today().year)
+ ".csv")